TripletMix: Triplet Data Augmentation for 3D Understanding
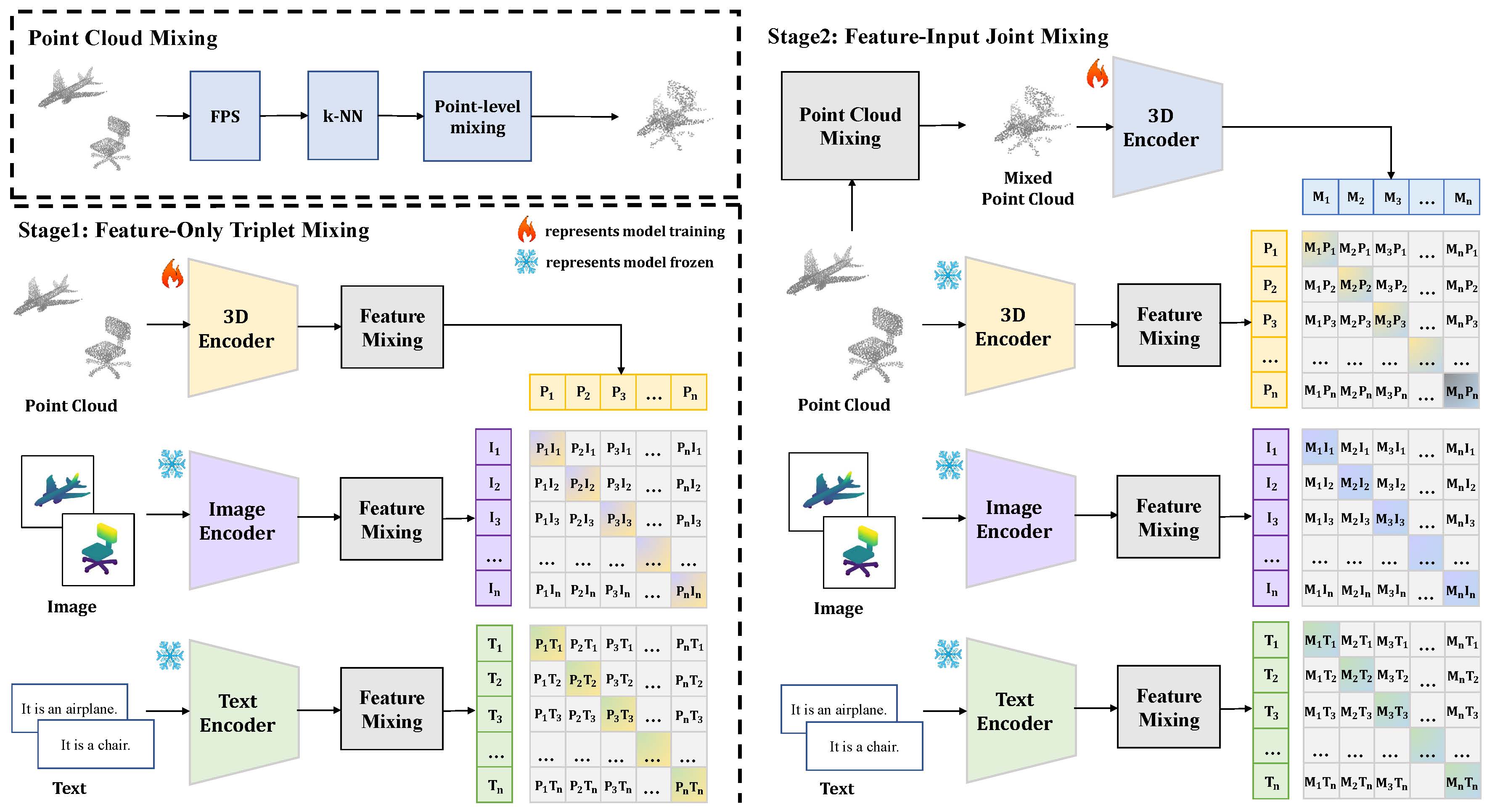
Overview
Data augmentation has proven to be a vital tool for enhancing the generalization capabilities of deep learning models, especially in the context of 3D vision where traditional datasets are often limited. Despite previous advancements, existing methods primarily cater to unimodal data scenarios, leaving a gap in the augmentation of multimodal triplet data, which integrates text, images, and point clouds. Simultaneously augmenting all three modalities enhances diversity and improves alignment across modalities, resulting in more comprehensive and robust 3D representations. To address this gap, we propose TripletMix, a novel approach to address the previously unexplored issue of multimodal data augmentation in 3D understanding. TripletMix innovatively applies the principles of mixed-based augmentation to multimodal triplet data, allowing for the preservation and optimization of cross-modal connections. Our proposed TripletMix combines feature-level and input-level augmentations to achieve dual enhancement between raw data and latent features, significantly improving the model's cross-modal understanding and generalization capabilities by ensuring feature consistency and providing diverse and realistic training samples. We demonstrate that TripletMix not only improves the baseline performance of models in various learning scenarios including zero-shot and linear probing classification but also significantly enhances model generalizability. Notably, we improved the zero-shot classification accuracy on ScanObjectNN from 51.3 percent to 61.9 percent, and on Objaverse-LVIS from 46.8 percent to 51.4 percent. Our findings highlight the potential of multimodal data augmentation to significantly advance 3D object recognition and understanding.
Materials
Citation
@inproceedings{wang2023tripletmix,
title={TripletMix: Triplet Data Augmentation for 3D Understanding},
author={Wang, Jiaze and Wang, Yi and Guo, Ziyu and Zhang, Renrui and Zhou, Donghao and Chen, Guangyong and Liu, Anfeng and Heng, Pheng-Ann},
booktitle = {arxiv},
year={2024}
}